
2·
7 months ago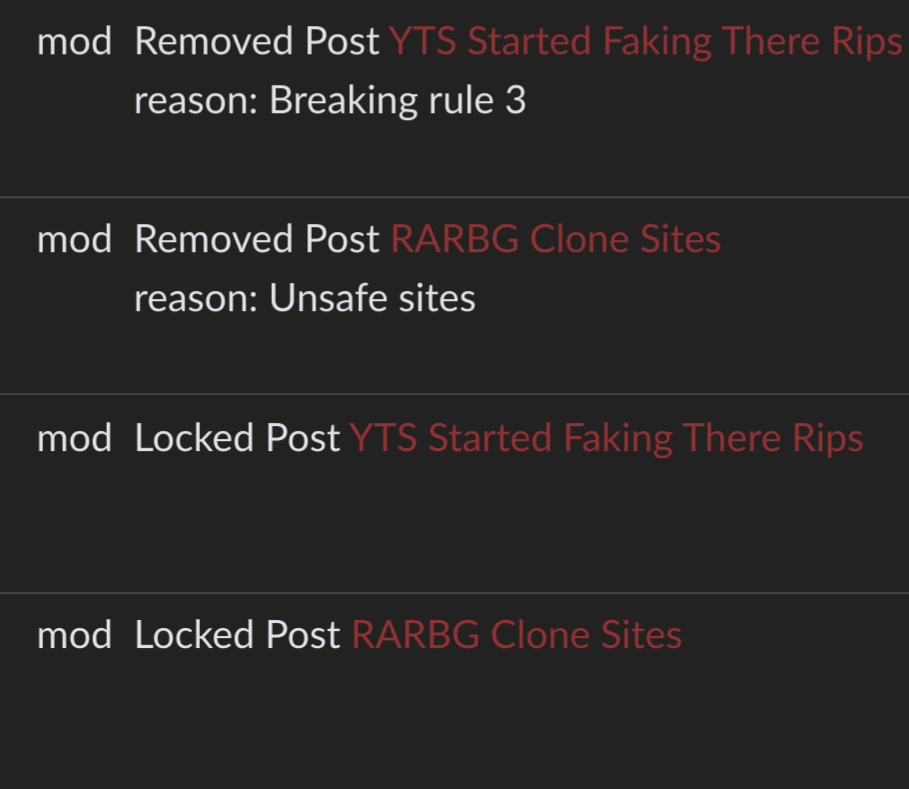
what were the titles of your posts?
The same system he was responsible for sending people into as part of his daily work, assuming they were still alive.
Why don’t you revert it back to the original structure and instruct makemkv to operate on that directory?

I’m still working on my part 1 😭 string parsing makes me feel so stupid haha. But I’m adamant on coming up with a “nice” solution even if the number of lines aren’t minimal. I’ve got something quite nice at the moment and I anticipate coming in under 100 lines (including whitespace, comments, and formatting).
I haven’t been parsing the input string character by character and instead have been parsing into native data structures. It makes the code more verbose but it’s how I want to do it. Unfortunately it does mean most of the time coming up with a solution is structuring the data so I’m hoping I come up with a faster way after a few days.

Don’t worry China, we super promise not to militarise it 🤞

It’s enough to wash away cars and everything else alongside it.
I hate it when they quote a time but no timezone. 10.37PM according to who?
As an alternative could he compile your program?

How do judges normally treat destruction of evidence? Do they not care who committed the crime and just make a ruling on how to infer it? I feel like the court would want to know who has committed something as serious as this but I’m not sure of the actual process for it.
I would be interested to hear if you get far down that road. It sounds infinitely more difficult than running code and timing it.
Are you able to expand what problem lead you to this question (out of curiosity)?
I was trying so hard to avoid doing this and landed on a pretty nice solution (for me). It’s funny sering everyone’s approach especially when you have no problem running through that barrier that I didn’t want to 😆
2oneight - if you replace from left to right you get 21ight or 21. This doesn’t work for part 2 as the answer should br 28.
I did this exact thing and hit the point where it didn’t work. I appreciated that the problem broke my code because it made me arrive at a better solution.
Im theory you could try counting CPU cycles or something analogous, or algorithmic complexity as the other commenter mentioned. You could also try to measure it in comparison to different code.
Outside of that, and in any practical sense, no you can’t. Performance measurements are dependent on the machine as much as the software.
If a car is hardware, and the driver is software, how would you measure the performance of the driver in the different cars? The only way I can think of is if you had 2 different drivers and could compare their times in both cars. If driver 1 is 2x as fast in car 1, and 2x as fast in car 2, you could say driver 1 has a score 2x higher than driver 2.
I’m not really sure how to interpret your comment but I’ll try my best. The edge case that causes some solutions to fail does not have any definition on how to handle it on the problem page. In other words, it does not state anywhere whether the correct interpretation of 1threeight is meant to be 18 or 13. If your solution replaces the words to numbers from left to right you end up with 13 as the value but it’s meant to be 18.
The example answers don’t cover this but you will realise something is wrong if you run it against your full problem. Community has been very helpful on providing pointers.
I arrived at the following solution for Day #1:
defmodule AdventOfCode.Day01 do
def part1(args) do
number_regex = ~r/([0-9])/
args
|> String.split(~r/\n/, trim: true)
|> Enum.map(&first_and_last_number(&1, number_regex))
|> Enum.map(&number_list_to_integer/1)
|> Enum.sum()
end
def part2(args) do
number_regex = ~r/(?=(one|two|three|four|five|six|seven|eight|nine|[0-9]))/
args
|> String.split(~r/\n/, trim: true)
|> Enum.map(&first_and_last_number(&1, number_regex))
|> Enum.map(fn number -> Enum.map(number, &replace_word_with_number/1) end)
|> Enum.map(&number_list_to_integer/1)
|> Enum.sum()
end
defp first_and_last_number(string, regex) do
matches = Regex.scan(regex, string)
[_, first] = List.first(matches)
[_, last] = List.last(matches)
[first, last]
end
defp number_list_to_integer(list) do
list
|> List.to_string()
|> String.to_integer()
end
defp replace_word_with_number(string) do
numbers = ["one", "two", "three", "four", "five", "six", "seven", "eight", "nine"]
String.replace(string, numbers, fn x ->
(Enum.find_index(numbers, &(&1 == x)) + 1)
|> Integer.to_string()
end)
end
end
My solutin in Elixir for both part 1 and part 2 is below. It does use regex and with that there are many different ways to accomplish the goal. I’m no regex master so I made it as simple as possible and relied on the language a bit more. I’m sure there are cooler solutions with no regex too, this is just what I settled on:
defmodule AdventOfCode.Day01 do
def part1(args) do
number_regex = ~r/([0-9])/
args
|> String.split(~r/\n/, trim: true)
|> Enum.map(&first_and_last_number(&1, number_regex))
|> Enum.map(&number_list_to_integer/1)
|> Enum.sum()
end
def part2(args) do
number_regex = ~r/(?=(one|two|three|four|five|six|seven|eight|nine|[0-9]))/
args
|> String.split(~r/\n/, trim: true)
|> Enum.map(&first_and_last_number(&1, number_regex))
|> Enum.map(fn number -> Enum.map(number, &replace_word_with_number/1) end)
|> Enum.map(&number_list_to_integer/1)
|> Enum.sum()
end
defp first_and_last_number(string, regex) do
matches = Regex.scan(regex, string)
[_, first] = List.first(matches)
[_, last] = List.last(matches)
[first, last]
end
defp number_list_to_integer(list) do
list
|> List.to_string()
|> String.to_integer()
end
defp replace_word_with_number(string) do
numbers = ["one", "two", "three", "four", "five", "six", "seven", "eight", "nine"]
String.replace(string, numbers, fn x ->
(Enum.find_index(numbers, &(&1 == x)) + 1)
|> Integer.to_string()
end)
end
end


{kind=link}
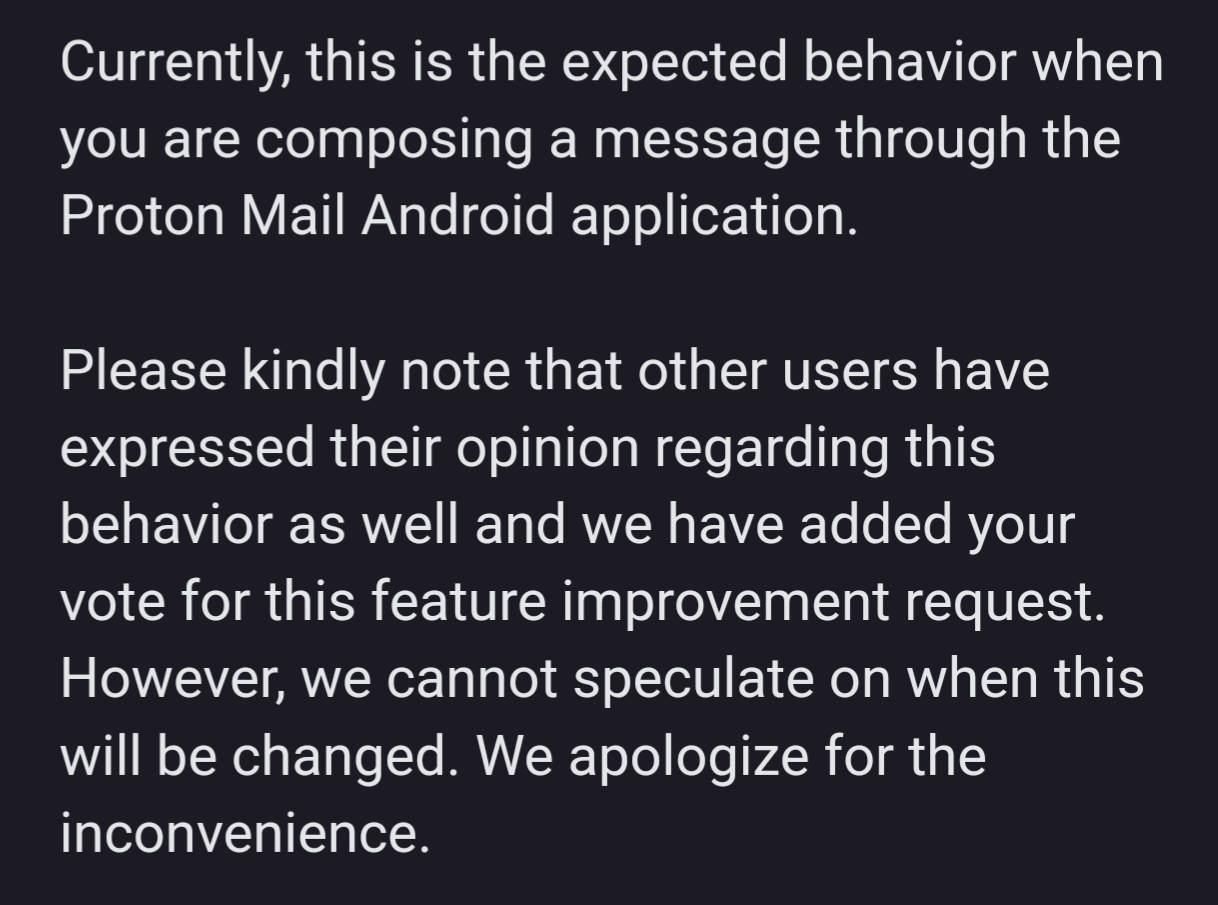{kind=link}
Desperate for that blue check money